基于OpenCV图像处理基础:打造你的视觉魔法棒我们了解到了图像的缩放。知晓了OpenCV的cv2.resize()函数提供了多种插值方法,通过interpolation参数指定。图像缩放时的插值方法是理解调整图像大小时像素值如何确定的关键。当你放大或缩小图像时,新的像素网格与原始像素网格并不完全对应,因此需要一种方法来估算新像素位置的颜色值,这就是插值的作用。接下来让我们来了解OpenCV中最常用的方法。
1.cv2.INTER_NEAREST – 最近邻插值
这是最简单、最快速的插值方法。对于目标图像中的每个像素点,它会找到源图像中与其位置最接近的那个像素,并直接复制该像素的值
数学原理
假设原始图像为src,目标图像为dst。我们要计算中坐标为(x’,y’)的像素值。首先我们需要找到它在src图像中对应的坐标(x,y)。这通过缩放比例scale来计算:
x = x' / scale_x
y = y' / scale_y
计算出来的(x,y)通常是浮点数,而像素坐标必须是整数。最近邻插值的做法非常直接:对(x,y)进行四舍五入,取最接近的整数坐标:
x_nearest = round(x)
y_nearest = round(y)
最后,将这个最近的原始像素值直接赋给新像素:
dst(x',y') = src(round(x) , round(y))
视觉效果
- 放大:产生块状效应(马赛克),图像看起来像素化,边缘呈锯齿状。
- 缩小:可能会丢失大量细节,因为某些原始像素可能根本不会被选中。
为什么产生块状效应?
当放大图像时,目标图像中一片相邻的像素(例如一个2×2或3×3的区域)在反向映射回源图时,它们的坐标可能在四舍五入后都指向了同一个源像素。因此,这一整片区域都会被赋予相同的颜色值,从而形成肉眼可见的色块(马赛克)。
优点:计算速度非常快;实现简单
缺点:图像质量差,尤其是在放大时;容易产生锯齿和块状伪影
适用场景
对速度要求极高,且图像质量要求不高的场合。或处理像素艺术等需要保持离散颜色块的图像。
2.cv2.INTER_LINEAR – 双线性插值(默认方法)
双线性插值不再是“非黑即白”地选择一个像素,而是认为新像素的值应该受到其周围像素的共同影响,且离的越近,影响越大。
数学原理(如果您并不理解下面的步骤在干什么,你可以看附录)
双线性插值考虑了目标像素在源图像中周围的2×2个临近像素。其本质上是在两个方向上分别进行线性插值
1.定位:和最近邻一样,我们首先计算出目标像素P(x’,y’)在源图像中的浮点坐标(x,y)
2.找到邻居:找到包围(x,y)的四个像素点,我们称之为Q11(x1,y1),Q12(x1,y2),Q21(x2,y1),Q22(x2,y2)。其中x1 = floor(x), x2 = x1 + 1,y1 = floor(y), y2 = y1 + 1。
3.X方向线性插值:
线性插值的核心是加权平均,权重与距离成反比。
首先,在y1行,我们根据x方向的距离,插值计算出点R1的值。f(R1) = f(Q11) * (x2 – x) + f(Q21) * (x – x1)(这里假设x2-x1=1,所以分母省略)
然后,在y2行,用同样的方法插值计算出点R2的值:f(R2) = f(Q12) * (x2 – x) + f(Q22) * (x – x1)
4.Y方向线性插值:
最后,我们根据y方向的距离,对刚刚计算出的R1和R2进行插值,得到最终P点的值:f(P) = f(R1) * (y2 – y) + f(R2) * (y – y1)
视觉效果
比最近邻插值平滑得多。在放大时,边缘和细节处可能会有些模糊,但不会像最近邻那样块状化。
为什么效果平滑?
因为每个新像素的值都是由周围四个像素颜色值平滑混合(加权平均)而来的,所以像素间的过度是渐变的,不会出现像最近邻那样的突变色块,从而产生了更平滑的视觉效果。但由于只是线性平均,它会抹平一些锐利的边缘,导致图像略显模糊。
优点
在计算速度和图像质量之间取得了较好的平衡
缺点
放大时仍然可能导致细节模糊。
适用场景
大多数通用图像缩放任务的良好默认选择。
3.cv2.INTER_CUBIC – 双三次插值
如果说双线性是用直线去拟合像素间的关系,那么双三次插值就是用更平滑的三次多项式曲线去拟合,从而更好地捕捉图像的细节变化。
数学原理(公式解析看附录)
双三次插值考虑了目标像素点在源图像中周围的4×4个邻近像素点。它的计算过程比双线性复杂得多。
其核心是使用一个三次卷积核函数,这个函数根据距离来计算16个邻居像素的权重。一个常用的三次样条函数形式如下:

$$
W(x) = \begin{cases} (a+2)|x|^3 - (a+3)|x|^2 + 1 & \text{for } |x| \le 1 \\ a|x|^3 - 5a|x|^2 + 8a|x| - 4a & \text{for } 1 < |x| < 2 \\ 0 & \text{otherwise} \end{cases}
$$其中 a 通常取-0.5或-0.75。这个函数定义了在一维上如何根据距离 x 分配权重。在二维图像中,目标像素 P(x, y) 的值由其周围 4×4 网格内的16个像素 Q(i, j) 的值与对应的权重相乘后求和得到:
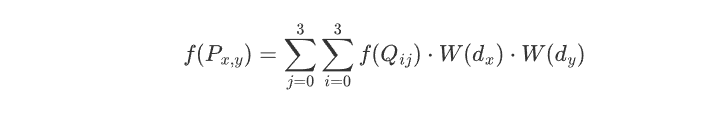
$$
f(P_{x,y}) = \sum_{j=0}^{3} \sum_{i=0}^{3} f(Q_{ij}) \cdot W(d_x) \cdot W(d_y)
$$视觉效果
通常比双线性插值产生更清晰、细节更丰富的图像。
为何更清晰,但可能产生“振铃”?
更清晰是因为三次函数比线性函数能更好地拟合像素值的局部变化趋势(可以理解为不仅考虑了“位置”,还考虑了“斜率”),因此能更好地保留图像的边缘和细节。
振铃效应:注意看上面的权重函数图,它在某些区域的值是负数。这意味着在计算加权平均时,某些邻居像素的贡献是“负”的。当一个像素点位于一个非常锐利的边缘(例如黑白交界处)附近时,这种负权重可能导致插值结果超出原始像素值的范围(比白更白,或比黑更黑),在边缘周围形成一圈微弱的“光晕”或“伪影”,这就是振铃效应。
优点
图像质量高,细节保留较好。
缺点
计算量更大;可能在边缘附近引入轻微的“振铃”效应
适用场景
当图像质量(特别是清晰度)比速度更重要时,如图像编辑和打印。
4.cv2.INTER_AREA -基于区域关系的重采样
这种方法的思路与前面几种完全不同。它在缩小图像时表现优异,因为它不是简单地挑选或混合几个点,而是考虑了像素所代表的“区域”。
数学原理
当缩小图像时,目标图像中的一个像素,实际上对应着源图像中的一个矩形区域。例如,将4×4的图像缩小到2×2,目标图像的左上角像素就对应了源图像左上角的一个2×2的区域。

$$
\text{dst}(x', y') = \frac{1}{S_x \cdot S_y} \sum_{j=0}^{S_y-1} \sum_{i=0}^{S_x-1} \text{src}(x' \cdot S_x + i, y' \cdot S_y + j)
$$INTER_AREA的原理就是计算这个源区域内所有像素的加权平均值,并将其作为目标像素的值。权重通常与像素被覆盖的面积比例有关。在最简单的情况下(缩放比例为整数),它就是对源区域内所有像素值求平均。
这种方法本质上是一种局部抽取和平均,它在采样前先进行了一次低通滤波(求平均),有效地抑制了高频信息,从而避免了混叠现象,如莫列波纹。
注意:当放大图像时,OpenCV的INTER_AREA实现会退化成与INTER_NEAREST类似的行为,因此它不适合用于放大。
视觉效果
- 缩小:能产生最平滑、最少伪影的结果,避免信息丢失或产生干扰图案。
- 放大:效果与INTER_NEAREST类似,不推荐。
优点
缩小图像时抗混叠效果最好,是大幅度缩小的首选。
缺点
不适合放大图像
适用场景
主要用于缩小图像,特别是当缩小比例较大时(如制作缩略图)。
5.cv2.INTER_LANCZOS4 – Lanczos插值
Lanczos插值是一种更高级的插值方法,它基于Sinc函数,被认为是理论上最理想的重建滤波器。
数学原理
在信号处理理论中,理想的重建滤波器是Sinc函数:sinc(x) = sin(πx) / (πx)。它的问题在于其支撑域是无限的,即需要考虑无限多个邻居像素,这在实际中无法做到。
Lanczos插值通过对Sinc函数进行加窗来解决这个问题,即只取Sinc函数的中心部分,并用一个窗口函数(Lanczos窗口)使其在边界处平滑地衰减到零。Lanczos核函数定义为:
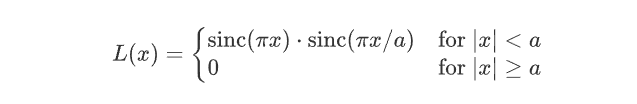
$$
L(x) = \begin{cases} \text{sinc}(\pi x) \cdot \text{sinc}(\pi x/a) & \text{for } |x| < a \\ 0 & \text{for } |x| \ge a \end{cases}
$$
这里的a是一个参数,决定了窗口的大小。在OpenCV中,INTER_LANCZOS4表示a=4,意味着它会考虑目标像素周围8×8的邻域。
与双三次插值类似,最终的像素值也是通过对8×8邻域内的64个像素进行加权求和得到,权重由二维的Lanczos核函数计算。
为何质量高,但振铃可能更明显?
高质量是因为Lanczos滤波器是对理想Sinc函数的良好近似,因此它能非常精确地重建信号,保留大量的图像细节和锐度。
更明显的振铃是因为Lanczos核函数同样具有明显的负波瓣,甚至比双三次核更强。这使得它在锐利边缘处的过冲现象(振铃效应)也可能更加明显。
视觉效果
通常能产生非常高质量的结果,图像清晰,细节保留好。
优点
通常是能提供更高的图像质量,特别是在放大时。
缺点
计算成本最高,速度最慢;振铃效应可能比双三次更明显。
适用场景 对图像质量有极高要求的应用,且可以接收较长的处理时间。
总结与选择建议
我们用一张表格来直观地对比这些方法:
| 插值方法 | 数学核心 | 优点 | 缺点 | 适用场景 (主要) | 计算成本 |
|---|---|---|---|---|---|
INTER_NEAREST | 四舍五入取整 | 最快 | 质量差,块状,锯齿 | 速度优先,质量其次 | 非常低 |
INTER_LINEAR | 2×2邻域线性加权 | 速度与质量的良好平衡 (默认) | 轻微模糊 | 通用缩放,默认选择 | 低 |
INTER_CUBIC | 4×4邻域三次多项式 | 质量较高,更清晰 | 较慢,可能边缘振铃 | 放大时追求高质量 | 中等 |
INTER_AREA | 像素区域求平均 | 缩小图像时抗混叠效果好 | 不适合放大 (同NEAREST),可能较慢 | 缩小图像,避免莫列波纹 | 中到高 |
INTER_LANCZOS4 | 8×8邻域Sinc窗函数 | 质量非常高,非常清晰 | 最慢,可能边缘振铃更明显 | 放大时追求最高质量 | 高 |
最终选择建议:
- 缩小图像: cv2.INTER_AREA 是你的不二之选,它能有效防止伪影,效果最自然。
- 放大图像(通用): cv2.INTER_LINEAR 是速度和质量的绝佳平衡点,也是OpenCV的默认选项。
- 放大图像(追求高质量): cv2.INTER_CUBIC 通常能提供比线性插值更锐利的结果。如果你的应用对质量有极致要求且不计成本,可以尝试 cv2.INTER_LANCZOS4。
- 速度至上: 如果性能是唯一的瓶颈,并且可以接受视觉上的瑕疵,那就选择 cv2.INTER_NEAREST。
代码示例
实践是检验真理的唯一标准。运行下面的Python代码,亲眼看看不同算法带来的差异把!你需要准备一张名为image.jpg的图片。
import cv2
import numpy as np
# 辅助函数: 准备图像进行并排显示
def prepare_for_display(image, text, target_width=200, target_height=150):
# 为了公平比较,将所有结果图统一缩放到相同尺寸进行展示
# 注意:这个缩放本身也会引入插值,但我们用AREA来做,以求最小化对比较的干扰
img_display = cv2.resize(image, (target_width, target_height), interpolation=cv2.INTER_AREA)
if len(img_display.shape) == 2:
img_display = cv2.cvtColor(img_display, cv2.COLOR_GRAY2BGR)
cv2.putText(img_display, text, (5, 15), cv2.FONT_HERSHEY_SIMPLEX, 0.4, (0, 255, 0), 1, cv2.LINE_AA)
return img_display
# 加载原始图像
try:
img_original = cv2.imread('image.jpg')
if img_original is None: raise FileNotFoundError
except FileNotFoundError:
print("Error: Could not load image.jpg. Creating a dummy image instead.")
img_original = np.zeros((100, 100, 3), dtype=np.uint8)
cv2.putText(img_original, "TEST", (10, 60), cv2.FONT_HERSHEY_SIMPLEX, 1.5, (255, 255, 255), 3)
# 目标尺寸 (放大 和 缩小)
height, width = img_original.shape[:2]
scale_factor_up = 4.0
scale_factor_down = 0.25
target_width_up, target_height_up = int(width * scale_factor_up), int(height * scale_factor_up)
target_width_down, target_height_down = int(width * scale_factor_down), int(height * scale_factor_down)
# --- 放大演示 ---
print("Processing upscaling...")
img_up_nearest = cv2.resize(img_original, (target_width_up, target_height_up), interpolation=cv2.INTER_NEAREST)
img_up_linear = cv2.resize(img_original, (target_width_up, target_height_up), interpolation=cv2.INTER_LINEAR)
img_up_cubic = cv2.resize(img_original, (target_width_up, target_height_up), interpolation=cv2.INTER_CUBIC)
img_up_lanczos = cv2.resize(img_original, (target_width_up, target_height_up), interpolation=cv2.INTER_LANCZOS4)
img_up_area = cv2.resize(img_original, (target_width_up, target_height_up), interpolation=cv2.INTER_AREA)
# 准备显示放大的图像 (将它们缩小以便在屏幕上比较)
disp_up_orig = prepare_for_display(img_original, "Original", 250, 200)
disp_up_nearest = prepare_for_display(img_up_nearest, "Up-Nearest", 250, 200)
disp_up_linear = prepare_for_display(img_up_linear, "Up-Linear", 250, 200)
disp_up_cubic = prepare_for_display(img_up_cubic, "Up-Cubic", 250, 200)
disp_up_lanczos = prepare_for_display(img_up_lanczos, "Up-Lanczos4", 250, 200)
disp_up_area = prepare_for_display(img_up_area, "Up-Area(like Nearest)", 250, 200)
row1_up = np.hstack((disp_up_orig, disp_up_nearest, disp_up_linear))
row2_up = np.hstack((disp_up_area, disp_up_cubic, disp_up_lanczos))
combined_up_scaling = np.vstack((row1_up, row2_up))
cv2.imshow(f'Upscaling x{scale_factor_up}', combined_up_scaling)
cv2.waitKey(0)
# --- 缩小演示 ---
print("Processing downscaling...")
img_down_nearest = cv2.resize(img_original, (target_width_down, target_height_down), interpolation=cv2.INTER_NEAREST)
img_down_linear = cv2.resize(img_original, (target_width_down, target_height_down), interpolation=cv2.INTER_LINEAR)
img_down_cubic = cv2.resize(img_original, (target_width_down, target_height_down), interpolation=cv2.INTER_CUBIC)
img_down_area = cv2.resize(img_original, (target_width_down, target_height_down), interpolation=cv2.INTER_AREA)
img_down_lanczos = cv2.resize(img_original, (target_width_down, target_height_down), interpolation=cv2.INTER_LANCZOS4)
# 准备显示缩小的图像
disp_target_w, disp_target_h = 200, 150
disp_down_orig = prepare_for_display(img_original, "Original", disp_target_w, disp_target_h)
disp_down_nearest = prepare_for_display(img_down_nearest, "Down-Nearest", disp_target_w, disp_target_h)
disp_down_linear = prepare_for_display(img_down_linear, "Down-Linear", disp_target_w, disp_target_h)
disp_down_cubic = prepare_for_display(img_down_cubic, "Down-Cubic", disp_target_w, disp_target_h)
disp_down_area = prepare_for_display(img_down_area, "Down-Area", disp_target_w, disp_target_h)
disp_down_lanczos = prepare_for_display(img_down_lanczos, "Down-Lanczos4", disp_target_w, disp_target_h)
row1_down = np.hstack((disp_down_orig, disp_down_nearest, disp_down_linear))
row2_down = np.hstack((disp_down_area, disp_down_cubic, disp_down_lanczos))
combined_down_scaling = np.vstack((row1_down, row2_down))
cv2.imshow(f'Downscaling x{scale_factor_down}', combined_down_scaling)
cv2.waitKey(0)
cv2.destroyAllWindows()
为了方便整体展示,我用到了prepare_for_display函数统一展示,建议你可以在每个例子中单独调试显示并观察它们的差异。
希望这篇结合了视觉效果、适用场景核数学原理的深度解析,能让你对图像插值有一个全面而清晰的认识!
附录
双线性插值解析
我将用一个非常直观的、分步的例子来为你彻底讲清楚这个过程。我们先忘掉图像,想象一个更简单的场景。
场景:测量一块田地的温度
假设我们有一块正方形的田地,我们只在四个角上安装了温度计。
- Q11 (左上角): 10°C
- Q21 (右上角): 30°C
- Q12 (左下角): 20°C
- Q22 (右下角): 40°C
现在我们的任务是:估算出田地正中央P点的温度。我们不能直接跑过去测量,只能根据这四个角的数据来“插值”计算。
双线性插值的思想是:“化繁为简”,将一个二维问题拆解成三个简答的一维问题。
第一步:一维线性插值
在解决二维问题之前,我们必须先掌握一维工具。
问题:在一条直线上,A点是10°C,B点是30°C.请问AB连线中点C的温度是多少?
这很简单,就是(10°C+30°C) / 2 = 20°C
再进一步:如果C点不是中心,而是距离A点70%的位置(距离B点30%)呢?
这时候就需要用加权平均了。C点的温度更接近B点。
C的温度 = A的温度 * 30% + B的温度 * 70%
C的温度 = 10 * 0.3 + 30 * 0.7 = 3 +21 = 24°C
这就是线性插值:一个点的值由其两端点的值根据距离进行加权平均得到。距离越近,权重越大。
第二步:进行第一次插值
现在回到我们的田地问题。我们的目标是P点,它在田地的正中央。
我们不能一步登天直接算P。我们先做一件事:沿着田地的上边缘和下边缘,找到与P点在水平位置上对齐的两个点。我们把它们叫做R1和R2。
- R1 在上边缘 Q11 和 Q21 的正中间。
- R2 在下边缘 Q12 和 Q22 的正中间。
现在,我们来计算R1和R2的“虚拟温度”:
1.计算R1的温度:
R1位于 Q11 (10°C) 和 Q21 (30°C) 这条线段的正中间。这是一个简单的一维线性插值问题! R1的温度 = (10°C + 30°C) / 2 = 20°C
2.计算R2的温度:
R2 位于 Q12 (20°C) 和 Q22 (40°C) 这条线段的正中间。这同样是一个一维线性插值问题! R2的温度 = (20°C + 40°C) / 2 = 30°C
由此我们实际上就求出了f(R1)和f(R2),这两个就是我们刚刚计算出的两个“虚拟温度”。它们不是田地里真实存在的测量点,而是我们为了解决最终问题而在水平方向上进行线性插值得到的第一批中间结果。它们代表了在上、下边缘与P点“对齐”的位置上,理论上应该有的温度值。
第三步:进行第二次插值,得到结果
现在的情况变得非常简单了!我们已经成功地将问题转化成了:
已知 R1 点的温度是 20°C,**R2** 点的温度是 30°C。**P** 点正好在 R1 和 R2 连线的正中间。请问 P 点的温度是多少?
这不又是一个我们最熟悉的一维线性插值问题吗!只不过这次是在垂直方向上。
P的温度 = (R1的温度 + R2的温度) / 2 P的温度 = (20°C + 30°C) / 2 = 25°C
我们成功地估算出了田地中央的温度是 25°C。
让我们把整个流程串起来,您就能明白f(R1), f(R2), 和 f(P) 到底在做什么了。
- 原始问题:根据四个角 Q11, Q21, Q12, Q22 的值,求中间点 P 的值。这是一个二维插值问题。
- 拆解步骤:
- 求 f(R1): 在第一个维度(x轴/水平方向)上,对上边缘的两个点(Q11, Q21)进行线性插值,得到一个中间值 R1。
- 求 f(R2): 同样在第一个维度(x轴/水平方向)上,对下边缘的两个点(Q12, Q22)进行线性插值,得到另一个中间值 R2。
- 求 f(P): 在第二个维度(y轴/垂直方向)上,对刚刚求出的两个中间值(R1, R2)进行线性插值,得到最终结果 P。
双三次插值公式解析
$$
W(x) = \begin{cases} (a+2)|x|^3 – (a+3)|x|^2 + 1 & \text{for } |x| \le 1 \\ a|x|^3 – 5a|x|^2 + 8a|x| – 4a & \text{for } 1 < |x| < 2 \\ 0 & \text{otherwise} \end{cases}
$$
让我们来分解这个公式的每一部分,理解它的含义:
W(x)是什么?W(x)是一个权重函数。它的作用是:根据一个邻近像素与目标插值点的距离x,来计算这个邻近像素应该占有多大的权重(影响力)。
x是什么?x是归一化的距离。在图像插值中,它代表了某个邻近像素的坐标与我们正在计算的目标点坐标之间的距离。例如,如果目标点在源图像中的x坐标是 25.7,那么它右侧的像素(坐标为26)的距离x就是26 - 25.7 = 0.3;它左侧的像素(坐标为25)的距离x就是25 - 25.7 = -0.7,取绝对值|x|就是0.7。
a是什么?a是一个可以自由调整的参数,它控制着插值曲线的“形状”。不同的a值会产生略微不同的插值效果。- 在OpenCV和许多其他库中,
a的典型值是 -0.5。 - 当
a = -0.5时,这个三次函数正好等价于Catmull-Rom样条(Spline),它具有很好的特性,能生成平滑且清晰的图像。 - 另一个常见值是
a = -0.75,这会产生更锐利一点的图像,但振铃效应也可能更明显。
- 分段函数的含义
for |x| ≤ 1: 这部分定义了与目标点最接近的两个邻居的权重。因为距离近,所以这部分是权重的主要贡献区域(函数图像的中心主瓣)。for 1 < |x| < 2: 这部分定义了与目标点次接近的两个邻居的权重。距离稍远,权重也相应变化。值得注意的是,在这段区间内,函数值是负数!这正是双三次插值会产生“振铃效应”的数学根源。负权重意味着在锐利边缘附近,插值结果可能会“过冲”,变得比周围最亮或最暗的像素更极端。otherwise: 当距离大于等于2时,权重为0。这就是为什么双三次插值只考虑 4×4 邻域的原因——更远的像素被认为没有影响。
解析完这个公式了,你可能会问,这只是一个一维函数 W(x),如何应用到二维的 4×4 像素网格上呢?
答案是利用该函数的可分离性 (Separability)。计算一个二维点 P(x, y) 的插值,可以分两步完成,这和双线性插值的思想类似,但更复杂:
- 行插值:对于 4×4 网格中的每一行(共4行),我们使用
W(x)对该行上的4个点进行一维插值,计算出与目标点P在水平位置上对齐的4个“虚拟点”的值。 - 列插值:然后,我们再使用
W(y)对上一步得到的4个“虚拟点”在垂直方向上进行一次一维插值,得到最终P点的值。
在数学上,这等价于一个单一的二维加权求和公式:
$$
f(P_{x,y}) = \sum_{j=0}^{3} \sum_{i=0}^{3} f(Q_{ij}) \cdot W(d_x) \cdot W(d_y)
$$
其中:
- f(Q_{ij}) 是 4×4 网格中第
(i, j)个邻居像素的值。 - d_x 是该邻居与目标点
P的水平距离。 - d_y 是该邻居与目标点
P的垂直距离。 - W(d_x) \cdot W(d_y) 就是该邻居像素最终的二维权重。
基于区域关系的重采样
情况一:整数倍缩小 (最简单、最直观的情况)
当缩放比例是整数时,例如将一个 400x400 的图像缩小到 100x100(即缩小4倍),情况非常简单。目标图像中的每一个像素都精确对应源图像中一个不重叠的 4x4 的像素块。
在这种情况下,INTER_AREA 的计算就是对这个像素块内所有像素值求算术平均值。
公式:
$$
\text{dst}(x’, y’) = \frac{1}{S_x \cdot S_y} \sum_{j=0}^{S_y-1} \sum_{i=0}^{S_x-1} \text{src}(x’ \cdot S_x + i, y’ \cdot S_y + j)
$$
公式解析:
- \text{dst}(x’, y’): 目标图像在坐标 (x’, y’) 处的像素值。
- \text{src}(x, y): 源图像在坐标 (x, y) 处的像素值。
- S_x, S_y: 分别是水平和垂直方向的缩放因子(例如,缩小4倍,则 S_x=4, S_y=4)。
- \frac{1}{S_x \cdot S_y}: 这是归一化系数,即源像素块中像素的总数。对于
4x4的块,就是 1/16。 - \sum_{j=0}^{S_y-1} \sum_{i=0}^{S_x-1}: 这是一个双重求和,遍历了源图像中对应于目标像素 (x’, y’) 的整个矩形像素块。
- \text{src}(x’ \cdot S_x + i, y’ \cdot S_y + j): 这部分是索引,用于定位源像素块中的每一个像素。例如,当 (x’, y’)=(0,0) 且 S_x=S_y=4 时,它会遍历
src图像中从 (0,0) 到 (3,3) 的所有像素。
通俗解释:这个公式就是在说,把源图像中那个 4x4 小方块里所有16个像素的颜色值加起来,再除以16,得到的结果就是新图像中那1个像素的颜色值。这本质上是一种盒状滤波器(Box Filter),起到了平滑和抗混叠的作用。
情况二:非整数倍缩小 (更普适的情况)
当缩放比例不是整数时,例如将一个 100x100 的图像缩小到 30x30(缩放因子为 100/30 \approx 3.33),情况就变得复杂了。目标像素的边界不再与源像素的网格完全对齐。
在这种情况下,源图像中的一个像素可能被分割,其一部分贡献给一个目标像素,另一部分贡献给相邻的目标像素。INTER_AREA 的计算会考虑这种面积覆盖关系,进行更精确的加权平均。
公式:
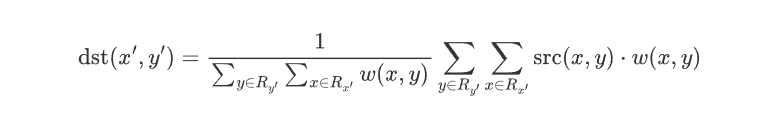
$$
\text{dst}(x’, y’) = \frac{1}{\sum_{y \in R_{y’}} \sum_{x \in R_{x’}} w(x, y)} \sum_{y \in R_{y’}} \sum_{x \in R_{x’}} \text{src}(x, y) \cdot w(x, y)
$$
公式解析:
- (x’, y’): 目标图像的像素坐标。
- R_{x’}, R_{y’}: 目标像素 (x’, y’) 在源图像上投影后所覆盖的源像素坐标范围。这是一个矩形区域。
- w(x, y): 这是最关键的部分——权重函数。它表示源像素 (x, y) 的面积被目标像素 (x’, y’) 的投影区域所覆盖的比例。这个值在 0 到 1 之间。
- 如果源像素 (x, y) 完全在投影区域内部,则 w(x, y) = 1。
- 如果源像素 (x, y) 完全在投影区域外部,则 w(x, y) = 0。
- 如果源像素 (x, y) 被投影区域的边界切割,则 w(x, y) 是一个介于0和1之间的小数,代表被覆盖的面积占该源像素总面积的百分比。
- \sum \sum \text{src}(x, y) \cdot w(x, y): 这是对所有相关的源像素进行加权求和。每个源像素的贡献值是其自身的颜色值乘以它被覆盖的面积比例。
- \frac{1}{\sum \sum w(x, y)}: 这是归一化项,即所有权重的总和。理论上,这个总和应该等于目标像素投影到源图像上的总面积(以源像素的单位面积为1来计算)。
通俗解释:想象你在源图像的像素网格上画一个代表新像素的“大方框”。这个大方框可能完整地盖住了某些源像素,也可能只盖住了另一些源像素的一角或一边。
- 对于每个被盖住的源像素,你计算出它被盖住了百分之多少(这就是权重 w(x, y))。
- 然后你用每个源像素的颜色值乘以这个百分比。
- 最后,把所有这些乘积加起来,就得到了新像素的颜色值。
这种方法精确地考虑了每个源像素对新像素的贡献,因此在任意比例的缩小时都能获得非常好的抗混叠效果,生成的图像平滑且自然。这也是为什么 INTER_AREA 在缩小图像时被认为是黄金标准的原因。
Lanczos插值核函数
Lanczos插值是一种基于截断Sinc函数的插值方法。它通过一个窗口函数(即Lanczos窗口本身)来限制理想的Sinc滤波器,使其在计算上可行。其核心是一维的Lanczos核函数L(x)。
公式:
$$
L(x) = \begin{cases} \text{sinc}(\pi x) \cdot \text{sinc}(\pi x/a) & \text{for } |x| < a \\ 0 & \text{for } |x| \ge a \end{cases}
$$
其中,标准的 Sinc 函数 定义为:

$$
\text{sinc}(x) = \frac{\sin(x)}{x}
$$
将 Sinc 函数的定义代入 L(x),我们可以得到更具体的表达式:

$$
L(x) = \begin{cases} \displaystyle \frac{\sin(\pi x)}{\pi x} \cdot \frac{\sin(\pi x/a)}{\pi x/a} & \text{for } 0 < |x| < a \\ 1 & \text{for } x = 0 \\ 0 & \text{for } |x| \ge a \end{cases}
$$
(注:当 x=0 时,sin(πx)/(πx) 的极限为1,因此 L(0)=1)
让我们深入理解这个公式的每个组成部分及其背后的思想。
- 理想的重建——Sinc 函数
- 在信号处理理论中,要想从离散的采样点(如图像像素)完美地重建出原始的连续信号,理想的插值滤波器是 Sinc 函数
sin(πx)/(πx)。 - Sinc 函数的问题在于它的支撑域是无限的(即
L(x)在x趋向无穷大时才衰减到0)。这意味着要计算一个点的插值,理论上需要用到无限多个邻居像素,这在实际计算中是不可能的。
- 在信号处理理论中,要想从离散的采样点(如图像像素)完美地重建出原始的连续信号,理想的插值滤波器是 Sinc 函数
- Lanczos 的解决方案——加窗
- Lanczos 的巧妙之处在于,它为无限的 Sinc 函数“开了一扇窗”。它只取 Sinc 函数最重要的中心部分,并让其在窗口边界平滑地降为零。
- 这个“窗”就是由第二个 Sinc 函数
sinc(πx/a)扮演的,它被称为 Lanczos 窗口 或 Sinc 窗口。
- 参数
a的作用- 参数
a定义了 窗口的“半径”,也就是我们考虑的邻域大小。它是一个正整数。 L(x)的定义表明,我们只考虑距离小于a的邻居像素(|x| < a),而忽略所有距离大于等于a的像素。- 在 OpenCV 中,
cv2.INTER_LANCZOS4意味着a=4。 - 当
a=4时,插值会考虑左右各4个像素,总共 8个像素 宽的邻域(在一维上)。在二维图像中,这就扩展为一个 8×8 的像素网格。
- 参数
- 核函数的形状与特性
- 主瓣 (Main Lobe):
L(x)在x=0处取得最大值1,并在x增加时迅速下降。这个中心的正值区域(|x|<1)贡献了最大的权重。 - 旁瓣 (Side Lobes):与双三次插值类似,Lanczos核函数在主瓣之外也有一系列的“旁瓣”,并且这些旁瓣会交替出现正值和负值。
- 振铃效应 (Ringing Artifacts):正是这些显著的负值旁瓣,使得Lanczos插值在处理高对比度、锐利的边缘时,容易产生比双三次插值更明显的“振铃”或“光晕”效应。这是为了追求极致的锐度而付出的代价。
- 高质量:由于
L(x)是对理想 Sinc 滤波器的良好近似,它能非常有效地保留图像的高频细节,因此通常能产生非常清晰、锐利的图像,被广泛认为是在放大图像时能达到的最高质量之一。
f(P_{x,y}) = \sum_{j=-a+1}^{a} \sum_{i=-a+1}^{a} \text{src}(x_{base}+i, y_{base}+j) \cdot L(x – (x_{base}+i)) \cdot L(y – (y_{base}+j))
$$
公式解析:- f(P_{x,y}): 目标像素在浮点坐标 (x,y) 处的插值结果。
- \text{src}(…): 源图像的像素值。
- (x_{base}, y_{base}): 8×8 邻域的左上角基准坐标。
- L(…): Lanczos 核函数。
- \sum_{j=-a+1}^{a} \sum_{i=-a+1}^{a}: 双重求和,遍历整个
(2a-1) x (2a-1)或(2a) x (2a)的邻域网格(具体取决于实现方式,OpenCV中为8×8,即a=4)。 - L(x – (x_{base}+i)) \cdot L(y – (y_{base}+j)): 这部分计算了每个邻居像素的最终二维权重,它等于该像素在x方向和y方向上分别计算出的Lanczos权重的乘积。
- 主瓣 (Main Lobe):
推荐书籍和文献(资源网上自己去收集吧)
书籍
*Digital Image Processing*(数字图像处理)
*Digital Image Warping*(数字图像变换)
论文
Cubic Convolution Interpolation for Digital Image Processing(图像处理之双三次插值)
Lanczos Filtering in One and Two Dimensions(Lanczos滤波从一维到二维)
Pyramidal Parametrics(金字塔参数-主要是跟基于区域的重采样有关的)
Summed-Area Tables for Texture Mapping(求和区域表-主要是跟基于区域的重采样有关的)
这里给出csdn的文章链接,希望也能去给点个赞和收藏。谢谢!